Store a writing sample of the student (fingerprint).
For all future assignment submissions, use that as baseline and return a similarity score from 0 to 1 to ensure they’re writing the assignments.
Similarity score of < 0.3 is flagged.
Implementation
Approach 1: Full LLM
We pass the fingerprint as context to the LLM along with the content to be compared. LLM returns a similarity score. Sample prompt:
You are an expert university evaluator, your aim is to determine if two distinct essays were written by the same person.
The subject matter is different.
Employ only stylistic factors such as sentence length style, general word choices, figurative and rhetorical tendencies, formatting and active/passive approaches.Add the expected response schema as input to the LLM as params.
{
"name": "similarity_response",
"description": "Check if the response is valid",
"parameters": {
"type": "object",
"properties": {
"similarity_score": {
"type": "int",
"description": "score from 0 to 1 where 0 is completely different and 1 is exact style match"
},
"score_reasoning": {
"type": "string",
"description": "Very short and simple non-technical human readable reasoning of what stylistic factors were compared and led to this score"
},
},
"required": ["similarity_score", "score_reasoning"]
}
}Disadvantages:
- LLMs are non-deterministic. The same content might give different results.
- Fully dependent on the quality of the LLM used.
Approach 2: Weighted LLM (preferred)
- Run the above LLM method, get results
- Run our custom stylistic evaluation, get results using traditional NLP
- Derive
similarity_scoreas a weighted average of both (70% LLM, 30% our custom eval etc)
Custom stylistic evaluation
Extract datapoints from fingerprint text:
- Distribution of sentence lengths (do they tend to use long sentences or short?)
- Function words ratio (how many/what kind of joining words do they use?)
- Punctuation distribution (do they use a lot of commas/hyphens/colons/semicolons?)
- Active/passive voice distribution (do they prefer active voice or passive voice?)
Function words ratio
- Function words are pronouns, conjunctions, prepositions etc
- Use an NLP library like
SpaCyto count function words ratio = (# function words) / (# total words)
Punctuation distribution
- Count # of sentences
dist = (# commas) / # sentences)- Do this for commas, semi-colons, hyphens etc
Result:
Weighted average of all these parameters.
result = (
(sentence_length_dist_sample/sentence_length_dist_fingerprint) +
(function_words_sample/function_words_fingerprint) +
(punctuation_dist_sample/punctuation_dist_fingerprint) +
(active_passive_sample/active_passive_fingerprint)
) / 4Running evals to benchmark
Prepare a set of at least 10 sample texts to test. These samples should not be changed and will be used for benchmarks.
Getting real writing is best; if not, take it from any fiction/non-fiction book.
(note that real writing is best because books have editors/reviewers etc who clean and normalize language)
Each example should have a fingerprint text and at least 1 text which is expected to pass (matching_answer) and at least 1 which is expected to fail (non_matching_answer).
Every time a change is made to code/LLM version, run these samples and see if it performs better/worse than the previous.
Recommended Todo:
Get to MVP
- Prepare a set of 10 example (fingerprint, matching_answer, non_matching_answer) input pairs
- Prepare your code and prompt
- Run those 10 examples against Gemini/GPT-4, modify till you get the max success % possible
- Host the best model possible on the Mac Mini
- Run those 10 examples on the model, that’s the max success % you can get.
Get to improved version
- Work on extracting the stylistic evaluation parameters from text
- Add code to compare it with the fingerprint
- Adjust weights of evaluation parameters to get max success % possible, trial and error
- Combine with LLM output, again tune weight of LLM output and stylistic parameters output to get max success % possible
Perf verification
- Measure time taken by the LLM to process 1 input. Extrapolate for
xinputs. This is the max load your system can handle, since the LLM is the bottleneck. - If you want better performance, swap the LLM with another of lesser parameters or a quantized model.
- Remember to compare benchmark and decide if performance gain is worth the accuracy loss.
System architecture
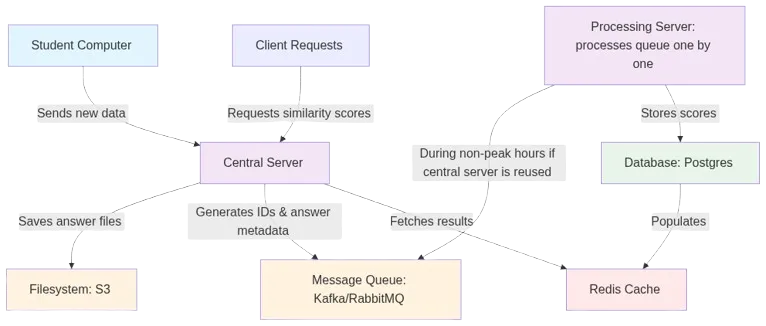
Note:
- For the MVP, everything can happen on the same server, ignore distributed filesystem/redis as well.
- The bottleneck is the LLM on the processing server.
Rough calculation:
input = (prompt + fingerprint + new input text) = 3000 tokens (~1000 words)
output = 300 tokens (~100 words)
# assume LLM takes 2s for input, gives 50 tokens/s output
total_time_per_doc = 8 seconds = 0.002 hours
# We need to process all docs in the queue within 12 hours
# (because then we'll start getting new docs)
max_allowed_time = 12 hours
max_docs_in_allowed_time = max_allowed_time/total_time_per_doc
= 12/0.002 = 6000 docsAdd servers/downgrade LLM accordingly to handle the load. Postgres/Redis/Kafka will be able to handle this load easily.







